
Posted on November 21, 2013
Efficient Geographic Coverage in SQL Server
Part 0: The Problem…
A fairly common problem in the real world is to make sure you have enough of something — hospitals, gas stations, water towers — to accommodate the need in a particular area. In Health care, where I finally got to tackle this problem in the real world, this is called “Network Adequacy”. In most places, the metric is basically the percentage of insured people that are within a certain distance of medical providers. The requirements change based on the provider type too… it may be important to have 90% of the population within 60 miles of a hospital, but you’d want an urgent care or primary care facility within, say, 20 miles of that 90%. The problem is compounded when you have to take into account the specialty of the providers. Being within 20 miles of a dentist, but 100 miles of a pediatric doctor or an OB/GYN is not sufficient.
It’s important to note that the distance is typically computed in actual travel time; it doesn’t help to be directly across the river from a hospital if you don’t have a bridge or a boat available. That version of the problem is wildly complicated but can be solved by tapping a travel time API such as google maps. These are complicated calculations; determining the distance between two points (a member and a doctor) in one second is probably doing pretty well.
But we have to do this for hundreds of thousands of members and tens of thousands of providers, for each provider type and specialty. That’s millions upon millions of seconds… we don’t have that sort of time. So we have to find a way to quickly pare down the results. The first and most obvious way is to eliminate the “drive time” requirement and focus first on the as-the-bird-flies distance… making some assumptions based on fastest interstate speeds, we know at least that we can’t do BETTER than a straight line, so at least we can limit the number of driving paths we have to calculate, and this is something we can do in pure SQL.
Part I: The Naive but State of the Art Solution
Most modern relational databases have geospatial features that allow you to “quickly” (simply at least) perform calculations such as the distance between two points without worrying much about the math, and the math is quite complex. There are plenty of references for this sort of math, but even assuming the earth is a sphere (it’s not — oil companies and pilots that need less than a 0.25% error must treat the earth as an ellipsoid), there is some advanced trigonometry involved.
SQL Server (since that’s what we’re working with at the moment, but other databases have similar capabilities), has a specific datatype called “geography” to help handle this. You can call
geography::POINT(Latitude, Longitude, SRID)
to generate the point. The SRID is the part that tells SQL Server if it should use an elliptical earth or a spherical one, or one of any number of minor variations. More than you ever wanted to know about this is available on a white paper here. We use SRID 4326, which is pretty standard.
If you have an address, you can get the Latitude and Longitude through many means, but for bulk US addresses I must recommend the people at the open source Data Science Toolkit.
Anyway, once you have it set up it’s fairly trivial to geocode all the points and store them in a database. At that point, you can create a spatial index on the geography column and life is good. Then, for each member, we run a nearest neighbor algorithm on the providers based on these geography columns and we can relatively painlessly count people that are within so many miles of a voodoo priest, or whatever we’re going for.
The dataset we’re using now runs about as efficiently as SQL Server will do natively with this query:
select MEMBER_ID
from MemberTable m
cross apply (select top(1) PROVIDER_ID from ProviderTable p with(index(geopoint_index))
where p.geopoint.STDistance(m.geopoint) <= (1609.34 * 10)
and p.ProviderType = 'PCP'This returns a list of only the members that have a PCP provider within 10 miles. This works OK, but not great. A few things about the query:
- It does not require a hint, but we put one in for clarity. Sometimes it is faster WITHOUT the hint, if the ProviderType filter prunes enough results to limit the number of comparisons enough that the STDistance calculation can work without the index
- The 1609.34 * 10 is converting meters to miles. We want Primary Care Physicians within 10 miles in this example.
- We can’t pre-calculate this — i.e. store a nearest neighbor for each member — because the filters and distances change based on need, and we need at least 20 something combinations that are subject to frequent change. It’s doable, but it takes database space and it’s not hugely elegant.
- I say “not great” because the run time on any given query can be around 10 minutes with our data-set and hardware, even if we’re using the best indexes. There’s much discussion about the black art of spatial index tuning, and it’s fascinating, but we’re pretty confident we eked out the last bit of speed with a naive query.
Part II: The next best optimization on the web…
Someone has already published a very clever optimization that improves upon this, and I’d be remiss if I didn’t sing its praises somewhat. The basic code looks like this:
DECLARE @start FLOAT = 1000; WITH NearestPoints AS ( SELECT TOP(1) WITH TIES *, T.g.STDistance(@x) AS dist FROM Numbers JOIN T WITH(INDEX(spatial_index)) ON T.g.STDistance(@x) < @start*POWER(2,Numbers.n) ORDER BY n ) SELECT TOP(1) * FROM NearestPoints ORDER BY n, dist
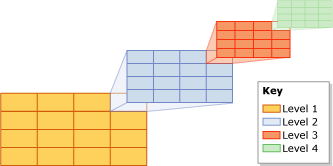
It’s based on the idea that SQL Server’s indexes are better at limiting the search for nearby neighbors if the distances are small, so this optimized SQL starts with a small distance and basically loops over increasing distances (exponentially) until it finds a match. This is all due to how SQL Server indexes these geographies… the full article is available from Microsoft, but the short version is that it splits the world into a grid and splits each section of that grid into grids and so on, four times. Each point is then indexed by which section of each grid it belongs. That way, if grids are, say, 1000 meters on a side, and you want to find points within 500 meters of a spot, you can narrow your search to only a few grids nearby the spot. Here’s the visual from Microsoft:
This is an improvement, but it has a few issues for our application:
- Our requirement that we filter on provider type and specialty mean that the query still spins on mismatched results… this affects filter selection; if we choose the spatial index then we lose the ability to ignore providers of unwanted types, which is very expensive, but if we choose an index based on type and specialty, we lose the performance improvement of the STDistance algorithm due to the geospatial index.
- We still can’t pre-calculate and cache everything without adding a large number of new columns to account for the varied distances, types, and specialties.
- The query doesn’t do well if it doesn’t find a match, and takes some tweaking to not go beyond a specific distance. That is, we could encounter situations where someone isn’t within any reasonable distance of a doctor, or that there’s even no doctor in our network of a given specialty. This query will spin for a while (until it runs out of numbers, I suppose), and eventually return NULL. This could be easily tweaked, but it’s still not as efficient as we need.
Part III: Dreaming Up Something Better
The balance we finally struck is based on something I came up with while I was asleep a few days ago (or at least, either while I was going to bed or waking up that night in some twilight sleep). I’m super excited about it, which is obviously why I made you wade through paragraphs of pre-material to get here. Anyway, it comes down to triangulating and comparing distances the way we learned in Boy Scouts.
I selected three more-or-less-arbitrary points. One in the south-western most point of Kentucky, one in the northernmost, and one in the easternmost. For each member and provider I built three columns containing the distance, in miles, to each of these three points respectively.

Now our query becomes:
select MEMBER_ID
from MemberTable m
cross apply (select top(1) PROVIDER_ID from ProviderTable p with(index(geopoint_index))
where
abs(m.distance_1 - p.distance_1) < 10
and abs(m.distance_2 - p.distance_2) < 10
and abs(m.distance_3 - p.distance_3) < 10
and p.geopoint.STDistance(m.geopoint) <= (1609.34 * 10)
and p.ProviderType = 'PCP'What’s going on here? Well, if you didn’t take an orienteering class in Boy Scouts, or if you’ve misplaced your geometry text, here’s the simple version: you can tell where any point is by its distance from three other points (as long as those three points aren’t in a straight line, that can cause a bit of confusion). That is, if I know a member is 100 miles from point A, 150 miles from point B, and 200 miles from point C, I know exactly where they are. This won’t work with one point, because they could be anywhere in a circle, and it normally won’t work with two points because the circles around two points meet twice (unless you’re exactly half way between them).
You can see this in the image below… this shows circles roughly 15 miles in width that measure the distance from each blue point to the red dot near the middle of KY. The three circles only intersect in one point (indicating the person at that point). Note that there are a few places outside Kentucky where two circles intersect, which is precisely why we need three.

While the triangulation of a single point is perfect, comparing distances is imprecise. If you enlarge the image you can see that the pattern where all three circles cross is an odd curved hexagon. If a provider were in one of the corners of that hexagon it would pass the three-distance test but still be more than 10 miles away. This is why we need the STDistance function at the end of the query. Still, the triangulation quickly eliminates most providers and it never eliminates a point that is actually within distance. The actual run time here is an order of magnitude faster than the other approaches we tried. Here’s the rundown for this version:
- Pre-calculating the three distances is very fast (three distance calculations for each member and provider — much less than calculating each and every distance between the two groups), takes up a known amount of space in the database, and only needs to be changed for addresses that change or new records (compared to pre-calculating a nearest neighbor, where every record would need to be re-evaluated if a new provider were added). This is manageable.
- Geospatial tuning is not needed. We added an index to the distance columns in each table, but those are traditional indexes; this query runs quickly with no geospatial index (because very few STDistance calls are actually made). Some day, when you can create a geospatial index WITH other columns, this may be very different.
- This works well for our problem… it may or may not be as fast for a single nearest neighbor calculation, but for network adequacy, which is somewhat different than nearest neighbor, this is an improvement.
I’m super pumped about this anyway. It’s probably not as exciting to you, but this is the sort of thing that makes me feel good. 🙂
—Chip